HyperLogLog 原理
作者:李康
HyperLogLog 算法用于统计大数据中数据的基数,即 multiset 中不同 key 的个数,HyperLogLog 是一种概率统计算法,即它无法精确地算出基数,有一定的偏差。
最直白的解释是,给定一个集合 S,对集合中的每一个元素,我们做一个哈希,假设生成一个 16 位的比特串,从所有生成的比特串中挑选出前面连续 0 次数最多的比特串,假设为 0000000011010110,连续 0 的次数为 8,因此我们可以估计该集合 S 的基数为 2^9。当然单独用这样的单一估计偶然性较大,导致误差较大,因此在实际的 HyperLogLog 算法中,采取分桶平均原理了来消除误差,下图是原始论文中关于该算法的伪代码:

根据精度要求选择合适的 m 值,对于集合中每一个元素进行哈希,根据哈希二进制的前 b 位来分配到合适的注册器中,再根据剩下的位来决定注册器的值,取连续 0 最大的值,而后再根据一系列消除误差的方法来得到最终的基数。
了解了 HyperLogLog 算法的基本原理过后,下面来看一下如何根据 HyperLogLog 来求两个数据集并集的基数。
使用 HLL 来求解并集的基数是 "无损(loss-less)",换句话说,它可以工作地很好。为了得到两个集合并集的基数,我们合并代表这两个集合的 HLL 数据结构来形成一个新的 HLL 数据结构,合并的操作很简单,把相同数字的注册器对作比较,选择其中较大的那一个注册器,作为新生成 HLL 注册器的值。上述合并 HLL 数据结构的算法等价于,先求两个集合交集,然后再生成 HLL 数据结构。
因此,我们可以使用 HLL 来估计两个集合交集的基数,即

那么能说
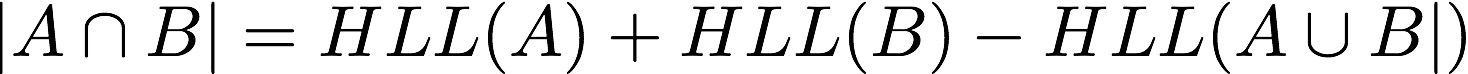
这个等式是成立的吗?已经有相关研究人员给了详细的分析,如果有兴趣可以去这里 https://research.neustar.biz/2012/12/17/hll-intersections-2/ 阅读。
下面给出上述论文得到的结论,论文定义了集合的两个测量标准:
overlap(A, B) = | A n B | / | B |, 其中 B 为基数更小的集合
cardinality_ratio(A, B) = | A | / | B |, 其中 B 为基数更小的集合
有了以上两个测量标准,论文的作者给出了一些有经验的规则,即何时上述计算交集基数的等式给出的结果是可接受的正确结果:
overlap(A, B) >= overlap_cutoff, AND
cardinality_ratio(A, B) < cardinality_ratio_cutoff
违背上述两个规则中的任何一个,错误率都会很高,在他们的结果中,界限值是基于桶(上面提到的注册器)确定的,对于 Redis 使用的桶的数量(16384),上述等式变为:
overlap(A, B) >= 0.05
cardinality_ratio(A, B) < 20
因此,在实际应用中,要充分考虑到应用场景需求与错误率之间的关系。
本文主要参考 http://dsinpractice.com/2015/09/07/counting-unique-items-fast-unions-and-intersections/ ,有兴趣地可以去阅读以下原文,其中还介绍了使用其它的方法来得到更好的交集基数的,在此不再赘述。